FAQ
Alpha Testnet Release
During the alpha release, Polybase DB is running all the indexers (validators) on the network so we can ensure development velocity and network protection during this early phase of the project. Therefore, all connections must be proxied by our testnet.polybase.xyz gateway.
Our next major release will open the network for anyone to be an indexer at which point the gateway won’t be necessary and the client will connect directly to the p2p network. We will continue to operate the gateway for as long as it is useful to our community.
What is your roadmap?
Polybase DB is committed to moving to a fully decentralized network as soon as possible. We have an ambitious roadmap for completing mainnet readiness.
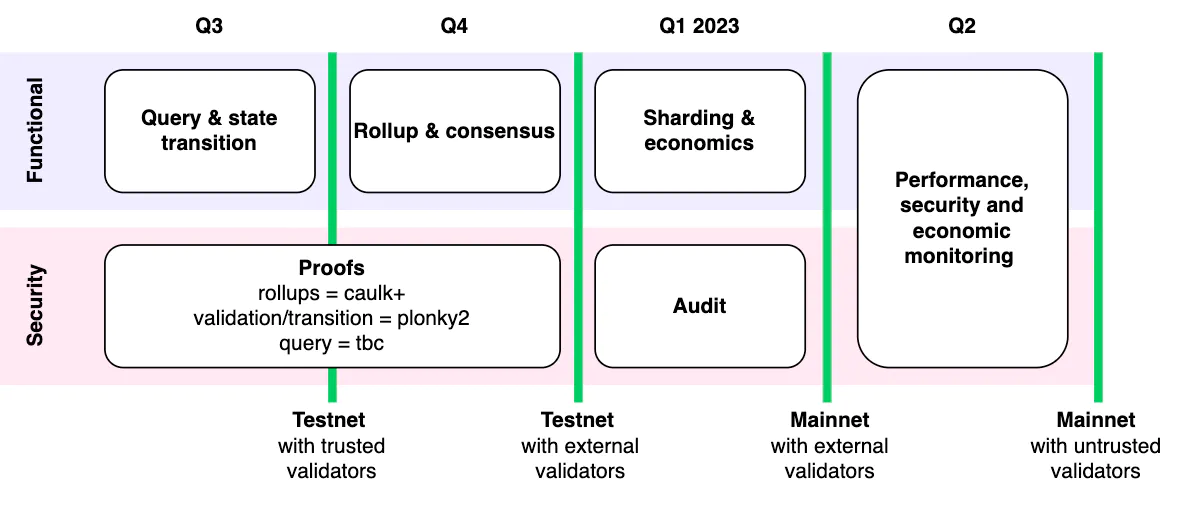
What is the Polybase DB architecture?
Polybase DB is a state zk-rollup protocol, with native support for pluggable data storage and indexing. While this architecture may look complex, our SDK handles all of the components you need out of the box, with a Firebase-like API.
The whitepaper has much more information about our architecture: https://polybase.xyz/whitepaper (opens in a new tab)
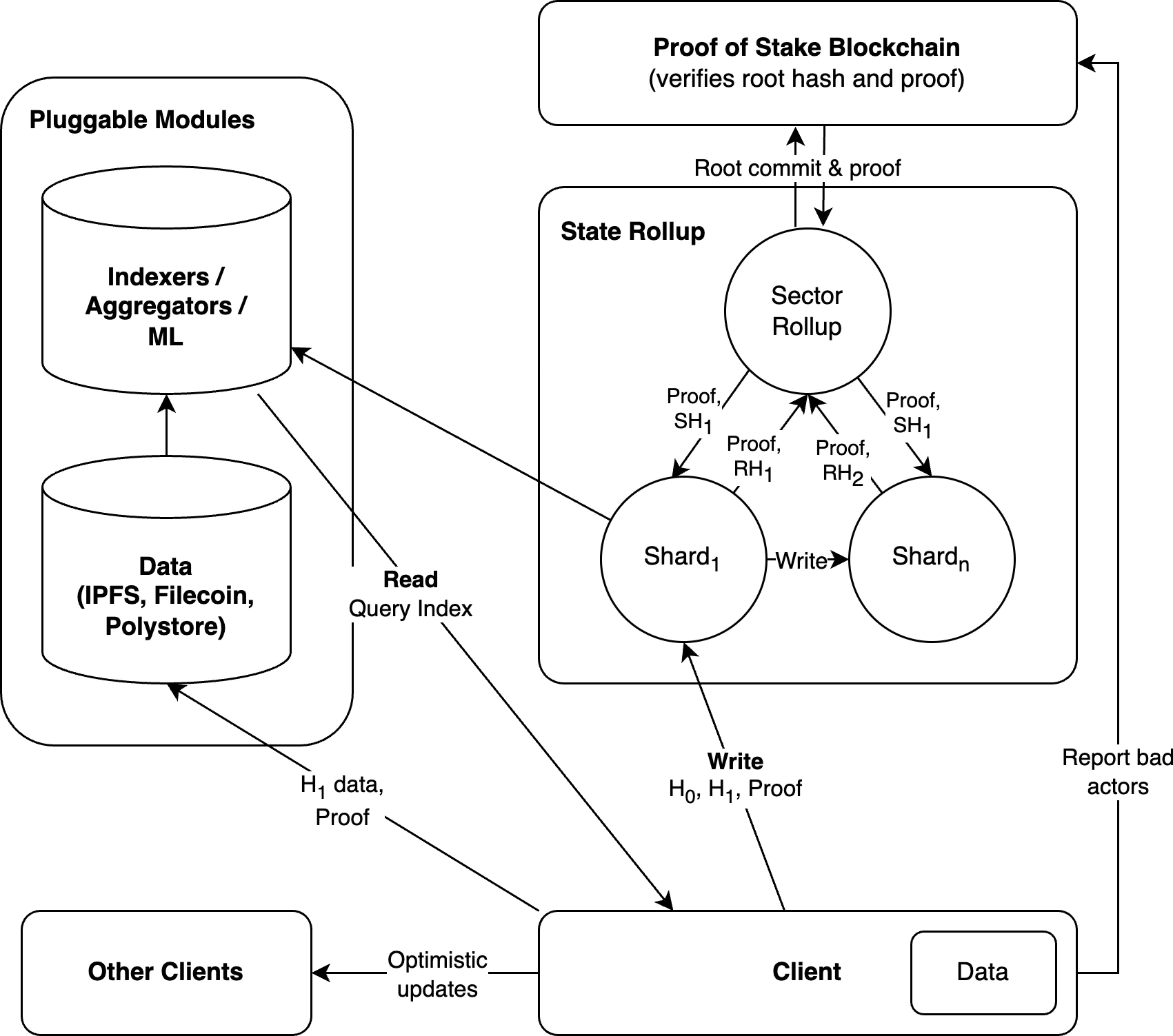
Where is the data on Polybase DB stored?
During Alpha Polybase DB runs all the nodes that store your data, but pluggable storage will be available soon.
Storage on Polybase DB is pluggable, that means as a developer you can choose the trade offs between the various storage and indexing options.
Here are some options:
- Local storage / custodial - you can store the data on the users device, most useful for highly private data and self-custodian use cases
- Decentralized storage protocol - such as filecoin, ipfs, arweave, etc
- Centralized storage - such as AWS S3, Postgres, Google BigTable, etc (if you use a centralized store, your data will be at risk of government censorship)
Out of the box, the default SDK implementation uses the Polybase DB datastore, which is a decentralized datastore with similar functionality to Firebase Firestore.
If data is stored off-chain, isn’t Polybase DB centralized?
Actually, no.
Our core innovation is storing data off-chain but validating it on chain with merkle tree root hashes and zk proofs. This allows you to inherit the security of a blockchain but the cost/scalability of a web2 database.
The whitepaper (opens in a new tab) has much more information about the methodology.
Can everyone see my data on Polybase DB?
During Alpha Polybase DB runs all the nodes that store your data, and data will be publicly visible.
It depends which storage option you choose:
- Local storage / custodial - no one else can see the data, only the user
- Decentralized storage protocol - the data is public, but you can encrypt the data to ensure only valid users can decrypt and read it
- Centralized storage - you can implement your own access controls
In all cases, data can be encrypted to ensure the best privacy protection. The Polybase DB SDKs provide the functionality to encrypt the data with a wallet. This could be a user’s Metamask wallet or a custodial wallet for the dApp.
Does every write / update transaction need to be signed?
Currently, yes every transaction needs to be signed (usually by the users's wallet if implemented in a non-custodial way). There's a way to create a "session key" which would be a symmetric key that is encrypted using the user's wallet. We're planning on adding utilities to the SDK to make creating a session key easier.
How do write permissions work on Polybase DB?
Writes to a Polybase DB collection are performed by calling a function defined on the schema of your collection. All updates must happen via these collection functions, there is no general .set() function.
There are two ways to define who can call these functions (and therefore update and create records in your collection). The following examples are two ways to do the same thing.
@call + code
You can allow anyone to call the function and handle the permissioning logic inside the function itself using code, for example:
@public // could also be written as @read @call
collection User {
id: PublicKey;
name: string;
// Anyone can call constructor
constructor (name: string) {
this.id = ctx.publicKey;
this.name = name;
}
// Anyone can call setName (you
setName(name: string) {
// Checking permissions with code
if (this.id != ctx.publicKey) {
error("Denied, not allowed");
}
this.name = name;
}
}@call(<field_name>)
You can add @call(<field>) directive which means that only specified actors can call the function, the field should either be a PublicKey type, or another collection (if you want to use delegate rules).
@read
collection User {
id: PublicKey;
name: string;
// Anyone can call constructor
constructor (name: string) {
this.id = ctx.publicKey;
this.name = name;
}
// Only user with public key can setName
@call(id)
setName(name: string) {
this.name = name;
}
}How do read permissions work on Polybase DB?
There are two ways to define read permissions in Polybase DB. You can either:
-
Encrypt the data using our encryption utilities - this allows you to control who can read data by sharing a secret key with them.
-
Add permission/authorization rules - you can define rules on your schema using the
@readand@delegatedirectives. This allows you to control who can query records.
How can the data on Polybase DB be accessed without going through the Polybase DB gateway?
While we are in testnet alpha, the only way to access the Polybase DB network is through the gateway. Once we open the network to our community, anyone may run the Polybase DB indexer reference implementation and directly connect to the P2P network (or use the SDK).
How can I verify Polybase DB is decentralized?
While we are in testnet alpha, there is no way to verify the decentralisation of the network. However, we are running the nodes behind the gateway in a way that will enable decentralisation as soon as we allow other participants to join the network.
Who pays for Polybase DB?
In most cases, at least initially, we expect it will be the developer who creates a collection who will ensure the database usage is paid for. In the future, we imagine that other protocols themselves will create mechanisms to pay Polybase DB directly. For example, a social network application may generate revenue (by running ads, charging a subscription, token appreciation, etc), and that protocol will have a mechanism to ensure that the balance on the Polybase DB protocol is always positive.
What happens if the developer stops paying?
Anyone who benefits from the data being maintained can choose to continue paying for the service. It’s similar to how ENS domains allow anyone to pay the registration fee even if the domain belongs to someone else.
There will also be an option to stake Polybase DB's native token and use that to pay for database usage.
How much does Polybase DB cost?
In testnet Polybase DB is free to use. For mainnet, we will charge developers to create collections and store data. You can expect the costs to be similar to Firebase Firestore.
How does Polybase DB make money?
When we reach mainnet, we will launch a utility token that will be used for payment and that token will accrue value as demand for the network grows, rewarding the early participants of the protocol.
How do you prevent spam attacks?
Invalid and spam transactions get rejected by the network before being processed because the zk proof is checked. Checking zk proofs is a fast/cheap operation, therefore no cost would be incurred for those.
What happens if Polybase (the company) shuts down?
Once we hit mainnet and full decentralization (scheduled for mid-2023), the network will continue to operate without our oversight. This is why creating a good cryptoeconomic system that incentives continued usage of the network is extremely important.
In fact, we intend to close down the company and replace it with a DAO (decentralized autonomous organisation) that will be responsible for the ongoing stewardship of the protocol.
Why do you have your own eth library?
We have our own eth library so that we can expose only the functions needed for our use case. The web3 and eth javascript libraries contain code for a lot of different use cases which increases the build size and makes it harder for users to work out which functions they should use.
What information is included in the per-block rollup posted to blockchains?
We rollup the current state of the whole Polybase DB root database at each block.
What are the security (or more so validation) benefits?
We use zk-proofs, which are generated on the client using the old hash, which creates a new hash and the proof that the new hash is valid - that is submitted to the rollup, which gets rolled up to the root hash.
This means the user does not even need to share the underlying data with the network, as the proof ensures the collection validation rules are followed.
The network only sees the hash of the old record, the hash of the new record, and the proof.
As everything is validated with proofs, you can prove any current (or existing state), making is very easy to create bridges to other blockchains (i.e. you can use Polybase DB data in your Ethereum smart contracts, etc)